Private Label, White Label, Wholesale partnerships available - EU, USA and UK - Free shipping from €75
What Is Scientific Reliability in Research: A 2026 Guide
Discover what is scientific reliability in research and learn how to ensure consistent, credible findings in your studies with our comprehensive 2026 guide.
TL;DR:
- Scientific reliability in research concerns the consistency and stability of measurements across time, raters, or items, rather than their correctness or validity. It is necessary but not sufficient for validity, and multiple types—test-retest, internal consistency, and inter-rater reliability—must be evaluated together to assess measurement quality. Ensuring reliability involves careful planning, training, robustness checks, and transparent reporting to produce trustworthy, reproducible findings.
Understanding what is scientific reliability in research is foundational to producing credible, reproducible findings, yet it remains one of the most misunderstood concepts in methodology. Many researchers conflate reliability with accuracy or treat it as synonymous with replication, when in reality it describes something more specific: the consistency and stability of a measurement across time, raters, or instrument items. This guide examines the definition of research reliability, its primary types, its relationship to validity, and the practical steps researchers can take to assess and strengthen it in their own work, drawing on frameworks updated through 2025 and 2026.
Table of Contents
- Key takeaways
- What scientific reliability in research actually means
- Types of research reliability and how to measure them
- Challenges and nuances in demonstrating reliability
- Practical steps for ensuring reliability in experiments
- My perspective on what researchers get wrong about reliability
- Supporting your research with reliable-grade lab supplies
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Reliability means consistency | Scientific reliability measures whether a tool produces stable, repeatable results, not whether those results are correct. |
| Reliability does not equal validity | A measure can be highly consistent yet systematically miss the intended construct entirely. |
| Three core types exist | Test-retest, internal consistency, and inter-rater reliability each address a distinct source of measurement error. |
| Analytic choices threaten robustness | Recent 2026 data show only 34% of reanalyses match original results exactly, highlighting the limits of any single analysis. |
| Use a battery of estimates | Combining multiple reliability indices gives a fuller measurement profile than relying on any one coefficient. |
What scientific reliability in research actually means
Scientific reliability concerns the consistency of measurement over time, across instrument items, or between raters, rather than the correctness of what is being measured. This distinction matters enormously in practice. A thermometer that always reads 2°C too high is perfectly reliable, producing the same offset every time, but it is not valid for measuring true temperature. The same logic applies to psychological scales, behavioral coding schemes, and any other scientific instrument.
The formal psychometric term for this property is measurement reliability, and it sits within the broader framework of classical test theory. That theory partitions any observed score into a true score and an error component. Reliability, under this model, is the ratio of true score variance to total observed score variance. Higher reliability means less error relative to signal.
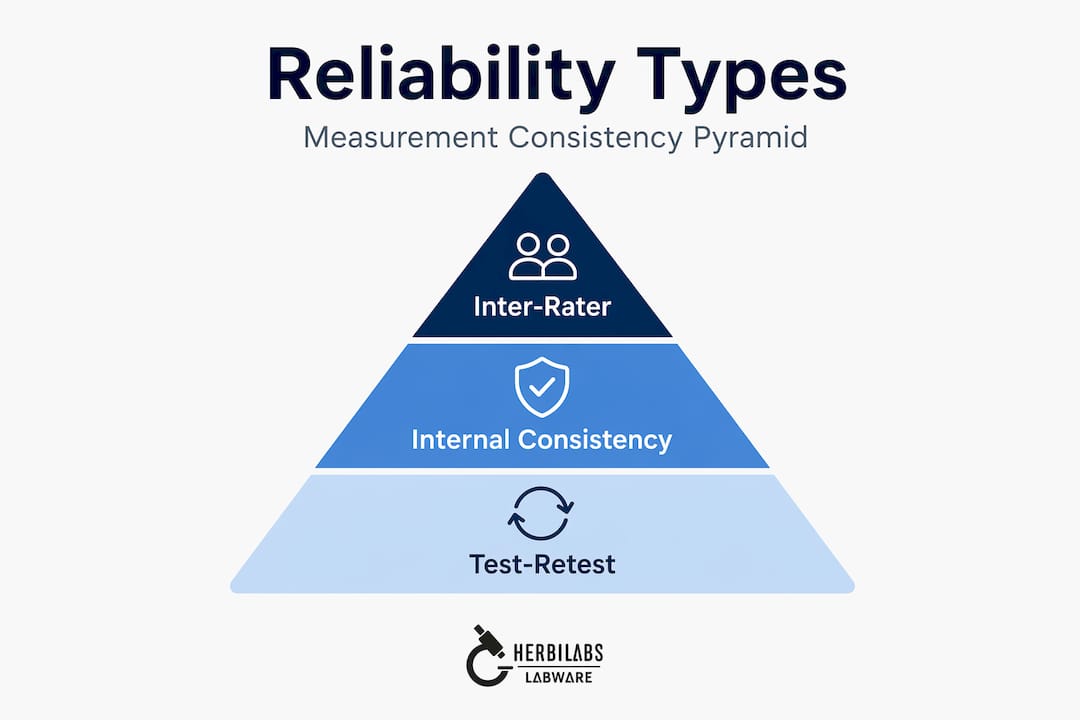
Reliability vs. validity: the critical distinction
Researchers frequently treat these two concepts as interchangeable. They are not. Reliability is necessary but not sufficient for validity. A scale measuring self-esteem by indexing finger length would produce highly consistent scores across administrations, yet would be entirely invalid as a self-esteem measure. Validity requires that reliable scores also map onto the construct they are intended to capture.
The table below summarizes the key contrasts between these two concepts:
| Dimension | Reliability | Validity |
|---|---|---|
| Core question | Does the measure produce consistent results? | Does the measure capture the intended construct? |
| Relationship | Prerequisite for validity | Cannot exist without some reliability |
| Assessment method | Correlation coefficients, alpha, kappa | Content, criterion, and construct evidence |
| Example failure | Scores fluctuate randomly between administrations | Scores are stable but measure the wrong thing |
Beyond this pair, two additional concepts are increasingly distinguished in contemporary methodology. Reproducibility refers to obtaining the same result from the same data using the same analytic procedure. Replicability means obtaining consistent findings using new data collected to answer the same research question. These three concepts are related but address fundamentally different layers of scientific evidence quality, and conflating them understates the complexity of verification in research.
Types of research reliability and how to measure them
Measurement reliability is not a single property. It is a family of properties, each addressing a different source of variance in observed scores. The three primary types are test-retest reliability, internal consistency, and inter-rater reliability.
-
Test-retest reliability assesses temporal stability by administering the same instrument to the same sample at two time points and computing the correlation between scores. A correlation of 0.80 or above generally indicates good test-retest reliability. The Rosenberg Self-Esteem Scale, for instance, has demonstrated a correlation of 0.95 over a one-week interval. The appropriate retest interval depends on the construct: traits expected to be stable over weeks should show high correlations, while state-level measures assessed over months may show lower stability without that necessarily indicating poor psychometric quality.
-
Internal consistency measures whether items within a scale are all tapping the same underlying construct. The most widely reported statistic is Cronbach’s alpha, where alpha at or above 0.80 indicates good consistency. Alpha is computed as the average of all possible split-half correlations for a set of items. If item scores intercorrelate strongly, alpha rises. If items pull in different conceptual directions, alpha falls, which signals a dimensionality problem in the scale rather than simple measurement noise.
-
Inter-rater reliability applies when human judgment is involved in coding, rating, or categorizing observations. It quantifies agreement between two or more independent raters. Cohen’s kappa is the standard statistic for categorical ratings; it corrects for the agreement that would occur by chance, unlike raw percentage agreement. Intraclass correlation coefficients (ICCs) are used for continuous ratings. Kappa values above 0.60 are typically considered acceptable, with values above 0.80 reflecting strong agreement.
Pro Tip: Do not rely on a single reliability metric to characterize your measurement instrument. Each of these three types targets a different error source, so a battery of reliability estimates gives a far more accurate picture of where measurement quality is strong and where it requires attention.
Challenges and nuances in demonstrating reliability
Even researchers who understand the three core types often encounter subtler problems when applying reliability concepts to real data. Several of these problems have become more visible in recent methodological literature.
One recurring issue involves analytic robustness, a concept that sits between reproducibility and replicability. Robustness asks whether a finding holds across different but equally justifiable analytic choices applied to the same dataset. A 2026 study found that only 34% of reanalyses matched original results exactly, and approximately 74% matched the original conclusions. That gap between “same exact results” and “same conclusions” reflects how much researcher degrees of freedom shape what gets reported as a reliable finding.
“Reliability requires multiple lenses, including robustness to analytic variation, rather than treating a single result or coefficient as sufficient evidence of measurement stability.”
This finding has direct implications for how researchers design and interpret studies. If two analysts applying legitimate but slightly different preprocessing pipelines, covariate selections, or model specifications reach different numerical conclusions, the apparent reliability of the original finding is genuinely in question, regardless of how high the original Cronbach’s alpha was.
A second challenge involves the limitations of Cronbach’s alpha itself. Alpha assumes that a scale is unidimensional and that all items contribute equally to the latent construct. When scales are multidimensional, alpha becomes misleading. A scale with two highly correlated subscales can produce high alpha not because all items measure one construct, but because the two clusters artificially inflate item intercorrelations. Psychometricians now recommend routinely examining factor structure and reporting omega coefficients, which are better suited to hierarchical and multidimensional scales.

A third issue concerns task-specific reliability in individual differences research. Intraclass correlations for cognitive tasks have been found to range as low as 0.09 to 0.29 in some paradigms, which means the measure is capturing almost no reliable individual difference signal. Researchers who use such tasks to compare individuals are essentially measuring noise, not ability.
Practical steps for ensuring reliability in experiments
Translating these principles into research practice requires deliberate design choices at multiple stages of a study. The following steps outline a structured approach to measuring and improving reliability in your own work.
-
Specify the reliability question before data collection. Decide which type of reliability is most relevant to your measurement context. Time stability matters most for longitudinal designs. Internal consistency matters most when using multi-item scales. Inter-rater reliability matters when observations require human judgment. Aligning the metric to the research design prevents post-hoc rationalization.
-
Train raters thoroughly and test agreement before the main study. For behavioral coding or clinical rating tasks, conduct a calibration phase where raters independently code a pilot sample and discuss discrepancies. Compute Cohen’s kappa or ICC on the pilot data. Only begin main data collection when agreement exceeds your pre-specified threshold.
-
Conduct confirmatory factor analysis alongside Cronbach’s alpha. Before reporting alpha, verify that your scale is unidimensional. If factor analysis reveals multiple dimensions, report omega coefficients for each factor rather than a single alpha for the whole scale. This reflects the actual structure of your instrument.
-
Perform robustness checks as a standard part of analysis. Run your primary analysis with at least two or three plausible alternative specifications: different covariate sets, alternative operationalizations of the dependent variable, or different preprocessing decisions. Document where conclusions remain stable and where they shift. This directly addresses analytic variability as a threat to research reliability in scientific studies.
-
Report reliability coefficients in full, with confidence intervals. Point estimates for alpha or kappa without uncertainty ranges obscure whether reliability is marginally acceptable or genuinely strong. Confidence intervals are especially important in small samples where reliability estimates are unstable.
Pro Tip: When measuring individual differences with reaction-time or cognitive tasks, compute ICCs stratified by within-person and between-person variance components. A task with low between-subject ICC is unsuitable for correlating with trait-level variables, regardless of how sensitive it is to within-person experimental manipulations.
Transparent reporting of reliability extends beyond tables in a manuscript. Pre-registration of reliability thresholds, sharing of coded data to enable independent inter-rater checks, and publicly available analysis scripts all contribute to a research record that others can actually verify.
My perspective on what researchers get wrong about reliability
I have reviewed enough manuscripts and datasets to say with some confidence that the most common reliability error is not computational. Researchers rarely miscalculate Cronbach’s alpha. What they do is treat a single acceptable coefficient as a certificate of measurement quality and stop there.
In my view, this single-metric habit is the deeper problem. A scale can clear the alpha 0.80 threshold while being factorially complex, temporally unstable, and sensitive to analytic decisions that were never documented. The coefficient looks fine; the measurement quality is not. The recent evidence that most reanalyses fail to exactly replicate original results makes this habit look increasingly untenable.
What I’ve found works better is treating reliability as a checklist rather than a single number. Does the measure show temporal stability? Are items internally coherent within a defensible factor structure? Do raters agree independently? Do conclusions hold under alternative analytic choices? Answering all four questions gives you a reliability profile, not just a number.
The shift in thinking required here is not trivial. It asks researchers to accept that their findings carry uncertainty from multiple sources simultaneously, and to communicate that uncertainty honestly rather than suppressing it behind a tidy coefficient. That transparency is what makes research trustworthy, and it is what distinguishes careful science from the kind of work that does not survive reanalysis.
— Ragnar
Supporting your research with reliable-grade lab supplies
Measurement reliability in your protocols depends not only on statistical rigor but also on the physical consistency of the materials you use. Variability introduced at the reagent or reconstitution stage compounds downstream analytical uncertainty, undermining even well-designed reliability checks.
Herbilabs supplies research-grade bacteriostatic water, sterile diluents, and reconstitution solutions manufactured to strict purity standards to minimize batch-to-batch variability. When your reconstitution materials are consistent, one major source of experimental error is removed before data collection begins. Explore Herbilabs’ high-purity reconstitution solutions or review the best laboratory reagents for 2026 to identify the supplies best matched to your reliability requirements. For more on how supplier consistency connects to research outcomes, the Herbilabs resource on quality control in research provides practical guidance.
FAQ
What is the simplest definition of research reliability?
Research reliability refers to the consistency of a measurement instrument across time, raters, or scale items. A reliable measure produces stable results under the same conditions, though stability alone does not confirm the measure captures the intended construct.
What is the difference between reliability and validity in research?
Reliability measures consistency; validity measures whether that consistent measurement actually reflects the target construct. A measure can be reliable without being valid, making reliability a necessary but insufficient condition for measurement quality.
What are the main types of research reliability?
The three primary types are test-retest reliability, which assesses stability over time; internal consistency, most often quantified with Cronbach’s alpha; and inter-rater reliability, which quantifies agreement between independent raters using statistics such as Cohen’s kappa or ICCs.
How do researchers measure internal consistency?
Internal consistency is most commonly measured with Cronbach’s alpha, where values at or above 0.80 indicate good consistency. For multidimensional scales, researchers should also run confirmatory factor analysis and report omega coefficients to avoid the distortions alpha produces when items do not form a single factor.
Why does analytic choice affect research reliability?
Different but equally defensible analytic decisions applied to the same dataset can yield different numerical results, a property assessed through robustness checks. A 2026 study found only 34% of reanalyses matched original findings exactly, demonstrating that a single analysis is rarely sufficient evidence of a reliable and robust finding.


